Part I - Complexity Analysis of Algorithms and Data Structures

Introduction
After much anticipation, I just completed Week 1 of Hack Reactor. The last 6 days have been filled with lots of introductions, lectures, pair programming, and sprints. Admittedly, coming into this experience I had my doubts about how much I could learn in 3 months; however, after just six days of being surrounded by the incredible instructors and teaching staff, I can safely say that the amount I learned in the last 6 days would have amounted to several months of learning on my own.
One thing that drew me to Hack Reactor was its emphasis on software engineering fundamentals. Although the majority of coding at HR is done in JavaScript, the language itself is merely a gateway to engage with deeper computer science concepts. To no surprise, the overarching theme of Week 1 has been learning about the fundamental concept of software engineering - the analysis of algorithms and data structures.
What is an Algorithm?
Definition: “Algorithm – is a set of steps to accomplish a task”
An algorithm can be thought of as a recipe or a step-by-step set of operations for solving a problem. You may have an algorithm for making a sandwich, driving from home to work in the morning, or using your phone to text a friend. In computer science, an algorithm is a set of steps that a computer program needs to follow to accomplish a task. Building efficient algorithms and knowing when to apply them, is what makes a superb software engineer.
Algorithm Design and Analysis
There are several ways to measure the efficiency of an algorithm - the main two being Time and Space (in memory). Time Complexity refers to the number of steps necessary to execute a program in relation to its input size. Whereas, Storage Complexity refers to the amount of memory space a program needs in order to accomplish its task. The effects of time and memory space may seem negligent when working with small input sizes, however, when operating over millions of data points, a poorly constructed algorithm can take hours or even days to complete.
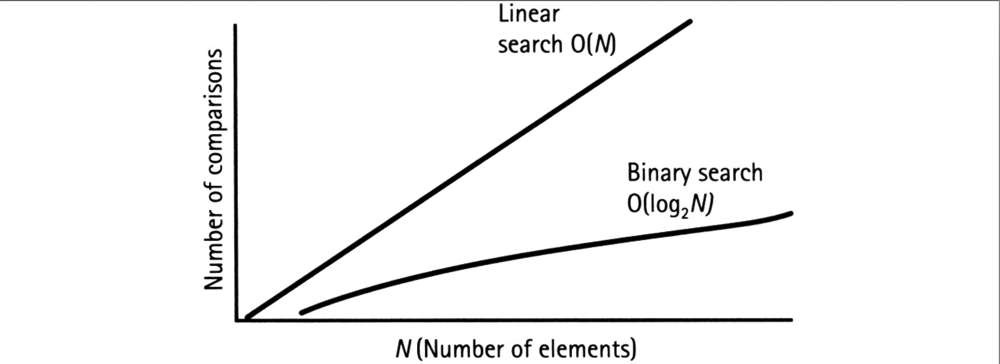
 This is best explained with an example. Say your task is to find your friend, Tom Kennedy’s phone number in a phone book consisting of 10,000 names. One way to solve this problem would be to go through each name, one by one, until you find the name you were looking for. In the worst-case scenario, it would take 10,000 lookup operations on 10,000 names. This is commonly referred to as linear search, meaning that for an input size of n, you have to perform n operations. Since all the names are in alphabatical order, another way to approach this problem is to use binary search. Instead of going through every name in the phone book, you can randomly open it at the “half-way” point (refer to Figure 1.1 above). Examine a random name on the page, for practical purposes let’s assume it was the letter ‘M’ and disregard the half that doesn’t contain ‘T’. Just in this one step, we were able save 5,000 operations. Next, we want to divide the remaining half of the phone book in half again (assume it’s letter ‘S’ now) and repeat the previous step of disregarding the half that doesn’t contain ‘T’. This saves us another 2,500 operations! Next we are going to divide the remaining half again and open to the page containing letter W, then U, and finally T. This took us all of 5 operations! Now if you repeat this step a several more times, you will be able to get to your friends name Tom Kennedy, but the bigger point here is that we were able to find our friend by checking approximately 10 names versus 10,000!
This is best explained with an example. Say your task is to find your friend, Tom Kennedy’s phone number in a phone book consisting of 10,000 names. One way to solve this problem would be to go through each name, one by one, until you find the name you were looking for. In the worst-case scenario, it would take 10,000 lookup operations on 10,000 names. This is commonly referred to as linear search, meaning that for an input size of n, you have to perform n operations. Since all the names are in alphabatical order, another way to approach this problem is to use binary search. Instead of going through every name in the phone book, you can randomly open it at the “half-way” point (refer to Figure 1.1 above). Examine a random name on the page, for practical purposes let’s assume it was the letter ‘M’ and disregard the half that doesn’t contain ‘T’. Just in this one step, we were able save 5,000 operations. Next, we want to divide the remaining half of the phone book in half again (assume it’s letter ‘S’ now) and repeat the previous step of disregarding the half that doesn’t contain ‘T’. This saves us another 2,500 operations! Next we are going to divide the remaining half again and open to the page containing letter W, then U, and finally T. This took us all of 5 operations! Now if you repeat this step a several more times, you will be able to get to your friends name Tom Kennedy, but the bigger point here is that we were able to find our friend by checking approximately 10 names versus 10,000!
Big-O Notation
There are two important ideas that help us determine the efficiency of an algorithm. First, run time measures the amount of time our algorithm takes to complete the entire task, which is a function of the input size. The second thing we need to know is the rate of growth of the running time or how fast our function grows with the increase in input size. In the example above, if the number of names in the phone book increases, the time it takes to find our friend’s name will increase as well. If we contrast linear search (blue line) with binary search (red line), we would see that as input size increases, linear search would need to perform n operations of n input size where as binary search would only perform log n operations for n size!
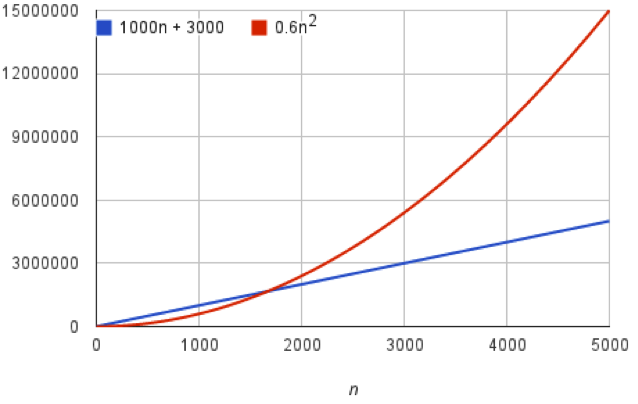 To demonstrate that the rate of growth of running time is by far the best indicator of function’s efficiency, let’s take a look at an algorithm f(n) = 6n^2 + 100n + 300 with input size n. As the input size grows, n^2 will come to dominate the function’s growth as n moves toward infinity. By dropping coefficients and constant terms, we are able to estimate the function’s complexity in the asymptotic sense, by focusing on the function’s upper bound or the worst-case run-time, which is represented by the big-O notation.
To demonstrate that the rate of growth of running time is by far the best indicator of function’s efficiency, let’s take a look at an algorithm f(n) = 6n^2 + 100n + 300 with input size n. As the input size grows, n^2 will come to dominate the function’s growth as n moves toward infinity. By dropping coefficients and constant terms, we are able to estimate the function’s complexity in the asymptotic sense, by focusing on the function’s upper bound or the worst-case run-time, which is represented by the big-O notation.
 The big-O notation simply approximates the asymptotic upper bounds of the function’s growth rate, by suppressing constant factors and low order terms. The letter O is used because it refers to the growth rate of a function, which is also referred to as order of the function. For our binary search example above, we can say that the running time is “O(lg n)”, meaning that the binary search run time grows at most f(lg n).
The big-O notation simply approximates the asymptotic upper bounds of the function’s growth rate, by suppressing constant factors and low order terms. The letter O is used because it refers to the growth rate of a function, which is also referred to as order of the function. For our binary search example above, we can say that the running time is “O(lg n)”, meaning that the binary search run time grows at most f(lg n).
Check out Part II to learn about Determining Complexity of Algorithms
For those of you learning how to code, I put together a curated list of resources that I used to learn how to code which can be found at breakingintostartups.com
Sign up for the Breaking Into Startups newsletter here for further guidance.
If you enjoyed this post, please share it with your friends! ❤ Also, I would love to hear about your stories in the comments below.
